
D1.1.3 Specification of word-sketch grammars and tools
The concept of a Word Sketch
A word sketch is a “one-page automatic, corpus-based summaries of a word’s grammatical and collocational behaviour” (Kilgarriff, 2004) and is a key feature of the Sketch Engine corpus management system (Kilgarriff, 2004, 2014). Word sketches have been introduced as a practical concept in computer lexicography to help lexicographers learn about how words behave in particular grammatical relations. They give a quick response to basic questions like
What are the most salient subjects of a given verb?
What are the most salient modifiers of a given noun?
What are the most salient verbs used with a given noun as object?
The key properties of a word sketch, as given in the definition are:
- they are data-driven, i.e. corpus-based, with links back to the underlying corpus evidence, i.e. allowing inspection of particular concordance lines which were the source for the computation
- they are produced in a fully automatic way, based on a hybrid rule-based and statistical approach (as explained further)
- they are clustered into meaningful language- and task-dependent relations, usually corresponding to the syntactic functions of the collocates
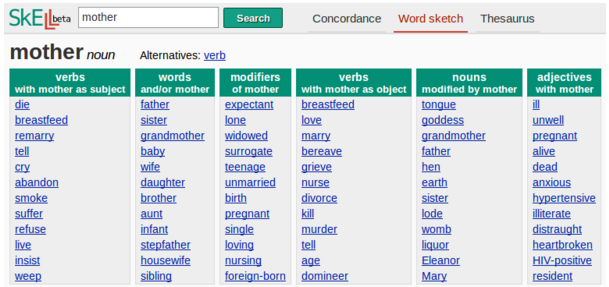
- they are easy to read, in a tabular format, with every column representing one grammatical relation (see Figure 1)

Figure 1: Example word sketch table from the SkELL
From a syntax theory point of view, word sketches represent an instance of the dependency syntax formalism allowing ambiguity, i.e. forming a dependency multigraph instead of a dependency tree. Similarly to a classical dependency relation, a word sketch relation is a binary relation, which:
- might be reflexive (reflexive relations are called “constructions”)
- might be symmetric
- is not transitive
- is labeled (i.e. named)
- is scored
Given that the relation is labeled, items of the relation are usually referred to as word sketch triples consisting of a headword, a relation name and a collocation, such as (resource; modifier; scarce). Such a triple is also assigned a score (a floating point number) representing the strength of the association between headword and collocation where particular semantics depends on the association measure that has been used to compute the score, as explained later.
From a more technical perspective, we actually deal with word sketch quintuples because as we mentioned earlier, one wants to keep links to particular corpus positions where a word sketch occurs, and hence the quintuples contain position of the occurrence of the headword and collocation in the corpus (as integer numbers) in addition to the triples. Therefore, instead of a single item such as (resource; modifier; scarce), one gets a set of quintuples (resource; modifier; scarce; pos1; pos2) corresponding to individual occurrences of these words in the given grammatical relation in the corpus.
Word Sketch Computation, Indexing and Scoring
The word sketch formalism has been fully implemented within the Manatee corpus management system (Rychlý, 2000; Rychlý, 2007). The implementation consists of three loosely coupled modules: the first one responsible for computing of word sketch triples, the second for efficient indexing that enables fast search and retrieval of word sketch items, and the third for scoring of indexed word sketches.
It is worth pointing out that particularly the module for word sketch computation is entirely independent of the module for word sketch indexing, allowing indexation of word sketch triples originating from various tools (not only from the module as provided in Manatee, but also e.g. from a common dependency parser).
In further subsections we describe each of these modules in detail.
Word Sketch Computation
The word sketch computation module in Manatee is based on the concept of a word sketch grammar, a plain text file specifying multiple word sketch relations as regular expressions over corpus positions, usually exploiting morphological annotation if the corpus. Definitions of word sketch relations are actually standard corpus queries written in the Corpus Query Language (Jakubíček, 2010) which is used in Manatee. An example of a simple word sketch relation definition is given below:
| =modifier 2:[tag=”ADJ”] 1:[tag=”NOUN”] 2:[word=”.*ing”] 1:[tag=”NOUN”] |
In this example, the modifier relation is defined using two CQL expressions (combined as logical OR) as any adjectives or -ing forms preceding a noun. In the CQL expression, the headword is always prefixed with a “1:” label and the collocation with a “2:” label. In the word sketch computation module, queries for all relations are executed over an already indexed corpus in Manatee, finally yielding the word sketch quintuples which are then subject to indexation.
A word sketch grammar is a set of word sketch relations, each of which may be defined using multiple corpus queries. The sketch grammar formalism is very flexible and features a number of metagrammatical concepts easing the handcrafting and maintenance of the grammar, such as use of M4 macros (Kernighan and Ritchie, 1977) and a large number of directives simplifying the query specification. Hereby we list some of the most important directives:
- STRUCTLIMIT - if set to a corpus structure such as paragraph or sentence, all query matching following this directive throughout the whole grammar will stop at structure boundaries.
- DEFAULTATTR - specifies default corpus attribute for all following queries in the sketch grammar.
- DUAL - the name of the relation following this directive is split on a slash character, where first part of the name corresponds to the name of the relation as given, and the second part names a dual relation with headword and collocation interchanged.
- SYMMETRIC - assumes that the relation following this directive is symmetric. In other words, SYMMETRIC is an instance of DUAL where both relations have the same name.
- COLLOC - this directive allows forming the collocation string from multiple query parts (labeled with numbers as seen in the example.
The following example sketch grammar facilitates all the directives listed above:
| *STRUCTLIMIT s *DEFAULTATTR tag *DUAL =modifier/modifies 2:"ADJ" "AD[JV]"{0,3} 1:"N" 1:"N" "ADJ"? 2:"ADJ" 1:"V.*" 2:"ADV" 2:"ADV" 1:"V.*" *DUAL =object/object_of 1:"V.*" "ADJ|ADV|DET"{0,3} 2:"N" *SYMMETRIC =and_or 1:"N" "ADJ.?"{0,3} [lemma="et|ou"] "DET.*"? "AD[JV]"{0,3} 2:"N" 1:"V.*" [lemma="et|ou"] [lemma="de|être|avoir"|tag="ADV"]? 2:"V.*" 1:"ADJ" "NOM" 2:"ADJ" =prep_phrase *COLLOC "%(3.word)_%(2.word)-p" 1:[tag="N.."|tag="AJ."] 3:"PR." 2:"N.." |
A full documentation to the sketch grammar formalism is available online.
So far sketch grammars for 26 languages have been devised during Sketch Engine development.
Alternative Approaches to Word Sketch Computation
As we announced earlier, the word sketch generation module in Manatee can be easily replaced by any other tool for generating dependency triples. In particular, one can easily exploit any existing dependency parser for generating word sketches, as we have shown in (Kilgarriff, 2014). Moreover, since word sketches do not require unambiguous representation of a text/sentence, they can be generated also from dependency graphs as was demonstrated in (Horák, 2009).
Usually converting the output of a dependency parser to the one necessary for word sketch indexing is very straightforward, and Manatee can directly do this task for the CoNLL dependency format.
Word Sketch Indexing
The word sketch indexing takes word sketch quintuples as input and stores them in an efficient indexing structure which is part of Manatee and is designed to enable fast execution of following queries:
- list of all headwords in the database
- for a given headword, what are the associated relations
- for a given headword and relation, what are the associated collocations
- for a given headword, relation and collocation, what are the corpus occurrences (positions) of headword and collocation
- for a given headword, relation and collocation, what is the number of corpus occurrences of headword and collocation
- for a given headword, relation and collocation, what is the associated score
Word Sketch Scoring
On top of an indexed word sketch database, the statistical components of Manatee finally perform computation of the score for each word sketch triple. A number of lexicographic association measures is implemented in the scoring module (such as T-score, MI-score etc.) with the default being a modification of the Dice coefficient called the logDice association score (Rychlý, 2008) defined for a given headword w1, relation Rand collocation w2as:
14 +log2 Dice w1; R; w2w1; R; *;w1; R; w2*; R; w2= 14 + log22 * w1; R; w2w1;R; *+*; R; w2
At the end of the computation, the scores are stored in the word sketch database.
Implementation and tools
The word sketch machinery as described above is all part of Manatee libraries written in C++. From a user perspective, each of the modules is controlled with single binary executable file used from Linux command line:
- word sketch generation: genws
- word sketch indexing: mkwmap
- word sketch scoring: mkwmrank
In the following we describe the usage and interaction between these three tools.
genws
genws takes four parameters:
- the name of the corpus (indexed in Manatee databases)
- the name of the corpus positional attribute which will be used for the lookup of headwords and collocates (usually a lemma, word form, or combination of lemma and part-of-speech abbreviation called a lempos)
- the output data path
- the word sketch grammar file (having .wsdef extension by convention)
The tools sequentially processes the given word sketch grammar file, evaluates all queries and send word sketch quintuples to its standard output as binary 64 bit integers. Its output can be inspected with standard Unix tools such as od:
genws bnc lemma /out/wsdb english.wsdef | od -t d8 -w40
0000000 24 0 27 27 30
0000050 27 0 24 30 27
0000120 41 0 42 49 51
0000170 42 0 41 51 49
0000240 36 0 57 76 80
![...]
E.g. the first line contains a word sketch quintuple for headword with id 24, relation with id 0, collocation with id 27 occurring on positions 27 (headword) and 30 (collocation).
mkwmap
The output of genws is normally directly passed to mkwmap which reads the word sketch quintuples from standard input and proceeds in three phases:
- sorting of the word sketch quintuples (numerically by headword, relation, and collocation) in a number of batches so that they fit into the computer memory
- joining of sorted batches
- writing the indices on disk
mkwmap takes a single obligatory argument pointing to the same data path as was used in genws. An example call would be:
genws bnc lemma /out/wsdb english.wsdef | mkwmap /out/wsdb
mkwmrank
mkwmrank is called after a successful word sketch generation and indexation by genws and mkwmrank. It operates on top of an existing word sketch database indexed by mkwmrank and updates this database with scores that it first computes. It takes a single obligatory argument pointing to the output data path (i.e. same argument as mkwmrank).
The whole processing pipeline would thus be:
genws bnc lemma /out/wsdb english.wsdef | mkwmap /out/wsdb; mkwmrank /out/wsdb
Performance and Effectivity
The word sketch format has been under continuous development since 2004. Besides various extensions to the word sketch functionality itself, such as multi-word sketches (Kilgarriff, 2012) or bilingual sketches (Baisa, 2014), we have been focusing on improvements in terms of both time and space efficiency of the word sketch computation.
Time complexity
The time necessary for compiling word sketch indices needs to be assessed according to the three independent phases (computation, indexing, scoring).
The most consuming part if word sketch computation, which depends on the number of relations and complexity of the corpus queries. The indexation phase is not very CPU intensive, log-linear with regard to the number of quintuples due to the sorting, and in terms of speed mainly dependent on the speed of the underlying storage performing I/O operations. The scoring phase is very fast since it facilitates existing indices, and usually takes less than 0.5 % time of the overall computation.
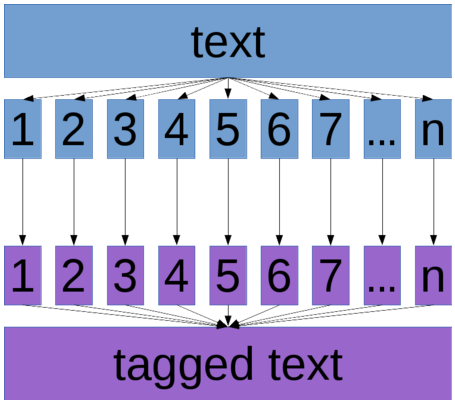
 Figure 2: Trivial parallelization
Figure 2: Trivial parallelization
From this follows that clearly any efforts towards speeding up the computation should be devoted to the computation, i.e. query evaluation phase. In (Pomikálek, 2012) we have shown a parallelization approach which, depending on the structure of the word sketch relation, allows close to a linear speed up of this phase with regard to the number of processing cores used.
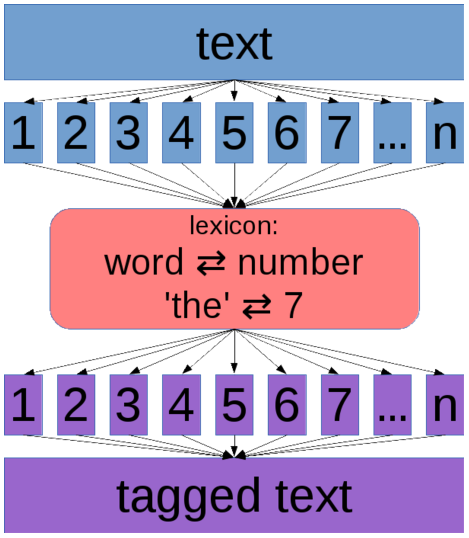
In natural language processing often parallelization can be done in the most trivial way: by splitting data to be processed into N parts and running N independent tasks (see Figure 2). However, in case of a corpus management system, this is often not possible because of the underlying string-to-number mapping which needs to be consistent across a single corpus, and hence shared during parallel processing. As such, it easily represents a bottleneck severely limiting potential speedup (see Figure 3). In (Jakubíček, 2014) we describe a general mechanism which deals with this issue and is called corpus virtualization.

Figure 3: Shared lexicon as a parallelization bottleneck
Space complexity
In 2015 a major overhaul of the indexing format has been performed in order to improve space efficiency. In the following table we provide a comparison of disk space occupied by indices in the two most recent word sketch formats:
| corpus | word sketch format 3 (since 2011) | word sketch format 4 (since 2015) |
| enTenTen13 (~22 billion tokens, Jakubíček et al., 2013) | ~370 GB | ~90 GB |
Qualitative Evaluation
Besides technical aspects of word sketches processing, a very important research question is the one of their quality. Since 2012 this has been subject to extensive research and is reported as a separate deliverable in D4.1: Methodology of Sketch Grammar evaluation.
Recent Extensions to the Word Sketches
In this section we describe recent enhancements to the basic word sketch functionality described so far.
Multiword sketches
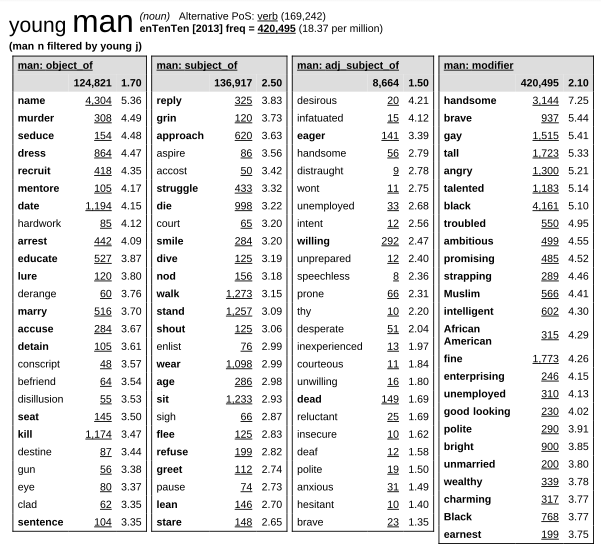
Originally word sketch headwords used to be always single word units -- depending on particular tokenization of the underlying corpus. In (Kilgarriff, 2012) the word sketch functionality has been extended towards multiword units. The approach taken is scalable in terms that the multiword unit length is not limited and only depends on the corpus evidence that can be found.
Technically multiword sketches are “filtered sketches”, e.g. for a noun phrase young man, one retrieves word sketches for man, looks up young among its collocates, and filters the word sketches only for corpus positions where young a collocate of man (in any relation). The same process is repeated starting from young with man as its collocate.
The resulting multiword sketch is depicted in Figure 4. Note that this process can be repeated to so as to retrieve word sketch for e.g. handsome young man.
Bilingual word sketches
Another extension to the word sketch functionality relates to the application of word sketches on parallel corpora and bilingual texts in general, e.g. to perform a contrastive collocational analysis of a word and its translation equivalent. This can be done in “three flavours”, all of which are described in detail in (Baisa, 2014):
- Bilingual parallel word sketch (BIP)
In case of two parallel corpora, i.e. corpora with existing alignment on sentence or paragraph level, we have devised algorithms for automatic computation of translation candidates based on such alignment. We then display word sketches for the top translation candidate, with aligned grammatical relations, and also show aligned segments with usages for individual collocations. An example parallel word sketch is provided in Figure 5.
 Figure 5: Bilingual parallel word sketch
Figure 5: Bilingual parallel word sketch
- Bilingual comparable word sketch (BIC)
In case of two comparable corpora, i.e. corpora which are not parallel but roughly of same size and same text types, we can leverage the translation candidates computer for the same pair of languages on two parallel corpora as in the first case, and proceed similarly, except we cannot show any aligned segments obviously.
- Bilingual manual word sketch (BIM)
In the last case, the user is responsible for providing the translation manually, and we then simply show the bilingual word sketch for the given translation.
 Figure 4: Multiword sketch for young man
Figure 4: Multiword sketch for young man
Longest-commonest match
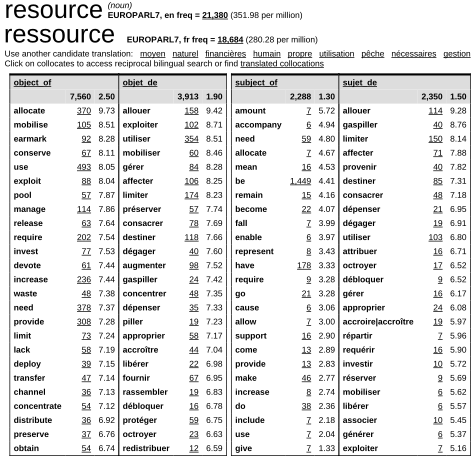
In some cases it is not very clear how the collocation is used with the headword. In simple cases where the collocation is an adjective and the headword is a noun, the whole phrase is immediately clear (young man), however in many others it is much more difficult: consider headword resource and collocation management in the relation modifies. Reviewing all the concordance lines actually reveals that the most common (hence longest-commonest) match is human resources management.
To spare users from inspecting concordance in these cases, recently the word sketch format has been enhanced so that it contains what we call longest-commonest match: the most common phrase built from the headword and collocation in the given grammatical relation. The algorithm for building longest-commonest match has been described in detail in (Kilgarriff, 2015).
References
BAISA, Vít, et al. Bilingual word sketches: the translate button. In: Proc EURALEX. 2014. p. 505-513.
HORÁK, Aleš; RYCHLÝ, Pavel; KILGARRIFF, Adam. Czech word sketch relations with full syntax parser.After Half a Century of Slavonic Natural Language Processing, 2009, 101-112.
JAKUBÍČEK, Miloš, et al. Fast Syntactic Searching in Very Large Corpora for Many Languages. In:PACLIC. 2010. p. 741-747.
JAKUBÍČEK, Miloš, et al. The tenten corpus family. In: 7th International Corpus Linguistics Conference CL. 2013. p. 125-127.
JAKUBÍCEK, Miloš; KILGARRIFF, Adam; RYCHLÝ, Pavel. Effective Corpus Virtualization. In: Challenges in the Management of Large Corpora (CMLC-2) Workshop Programme. p. 7.
KERNIGHAN, Brian W.; RITCHIE, Dennis M. The M4 macro processor. Bell Laboratories, 1977.KERNIGHAN, Brian W.; RITCHIE, Dennis M. The M4 macro processor. Bell Laboratories, 1977.
KILGARRIFF, Adam, et al. Itri-04-08 the sketch engine. Information Technology, 2004, 105: 116.
KILGARRIFF, Adam, et al. Finding multiwords of more than two words. Proceedings of EURALEX2012, 2012.
KILGARRIFF, Adam, et al. The Sketch Engine: ten years on. Lexicography, 2014, 1.1: 7-36.
KILGARRIFF, Adam, et al. Extrinsic corpus evaluation with a collocation dictionary task. In:Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC 2014). 2014.
KILGARRIFF, Adam, et al. Longest–commonest Match. 2015.
POMIKÁLEK, Jan; JAKUBÍCEK, Milos; RYCHLÝ, Pavel. Building a 70 billion word corpus of English from ClueWeb. In: LREC. 2012. p. 502-506.
RYCHLÝ, Pavel, et al. Korpusové manažery a jejich efektivní implementace. 2000.
RYCHLÝ, Pavel. Manatee/bonito-a modular corpus manager. In: 1st Workshop on Recent Advances in Slavonic Natural Language Processing. within MU: Faculty of Informatics Further information, 2007. p. 65-70.
RYCHLÝ, Pavel. A lexicographer-friendly association score. Proceedings of Recent Advances in Slavonic Natural Language Processing, RASLAN, 2008, 6-9.
Attachments (5)
- fig1.png (99.2 KB ) - added by 10 years ago.
- fig2.png (44.3 KB ) - added by 10 years ago.
- fig3.png (70.7 KB ) - added by 10 years ago.
- fig4.png (113.1 KB ) - added by 10 years ago.
- fig5.png (88.5 KB ) - added by 10 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip