
Corpus Annotation Tool
Dynamic PoS annotation framework
The system for part of speech (PoS) annotation of sentences was created. The aim is to create tool for easy and fast creation of small annotated corpora for languages without linguistics resources.
The tool is optimized for the following priorities:
- Simple tool for instant usage.
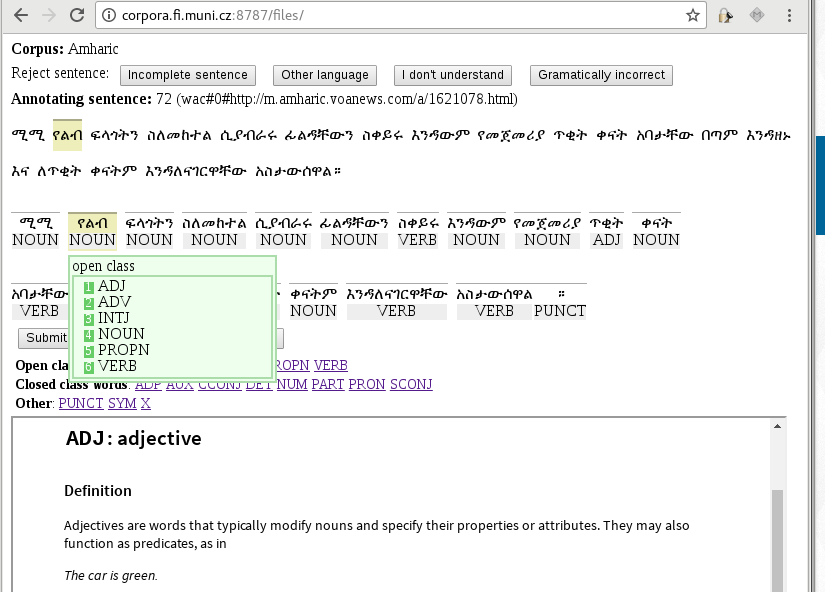
The client part of the tool is a web application which works in any browser, it requires small amount of all resources (memory, internet connection, screen size), it could be used even from mobile devices (tablets, phones). - Using small standard tag set.
If possible, we have used Universal Dependencies (UD) tag set (version 2). It is well documented and used for many different languages. The main description of the tags is directly included in the tool with links to the UD site. - Fast navigation.
Users can use mouse or keyboard for navigation, only one or two mouse clicks or key strokes are needed for annotation of one token. All sentences are pre-annotated via an builtin adaptive tagger and only incorrect annotation have to be corrected by users. - Clean texts.
Users can (and are instructed to) reject to annotate a sentence if the sentence is not clear.
The tool was used to annotate texts in 6 languages by 16 annotators in total. Czech and Norwegian corpora were annotated mainly for evaluation reasons, there are several PoS annotated (including UD tag set) corpora for both languages. Annotation of 4 Ethiopian languages was used to build respictive PoS taggers which are part of the HaBiT system.
Online statistics from the annotation are available here.

Last modified
9 years ago
Last modified on Jun 1, 2017, 11:50:16 AM
Attachments (1)
-
coran-screenshot.png
(84.4 KB
) - added by 9 years ago.
Screen shot of the Corpus Annotation Tool
{kind=link}
Download all attachments as: .zip
Note:
See TracWiki
for help on using the wiki.